Ahmed OSMAN
Ingénieur IA chez Nuiva
En tant que Data Scientist passionné, je combine des compétences analytiques avancées avec une expertise en programmation et en modélisation pour résoudre des problèmes complexes et transformer les données en décisions éclairées.
Je travaille actuellement comme Ingénieur IA chez Nuiva, où je suis responsable du développement et du déploiement de modèles d'apprentissage automatique pour améliorer la performance des produits de l'entreprise.
![]()
![]()
![]()
Apprentissage - Détection Automatique des Séries de Requêtes Juridiques
Ce projet vise à automatiser la classification des séries de requêtes juridiques grâce à une combinaison de techniques de science des données. Il a été développé dans le cadre de mon apprentissage en Master de Data Science à l’Université Paris-Saclay et au Conseil d’État (France), un processus essentiel pour optimiser le traitement des données au sein de cette institution.
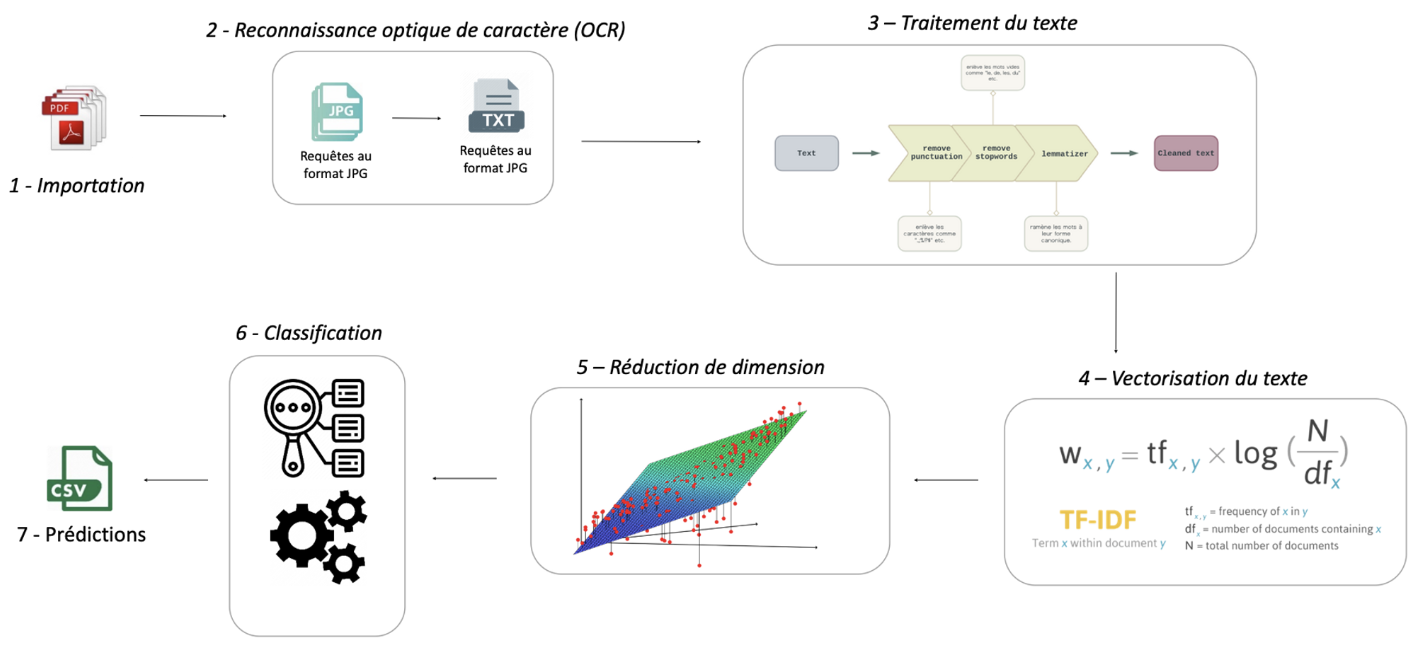
Reconnaissance Optique de Caractères (1 - OCR)
Ce dossier contient les scripts et ressources utilisés pour convertir des documents juridiques numérisés en texte exploitable par machine. La technologie OCR constitue la première étape du processus, transformant les documents physiques en un format numérique analysable.
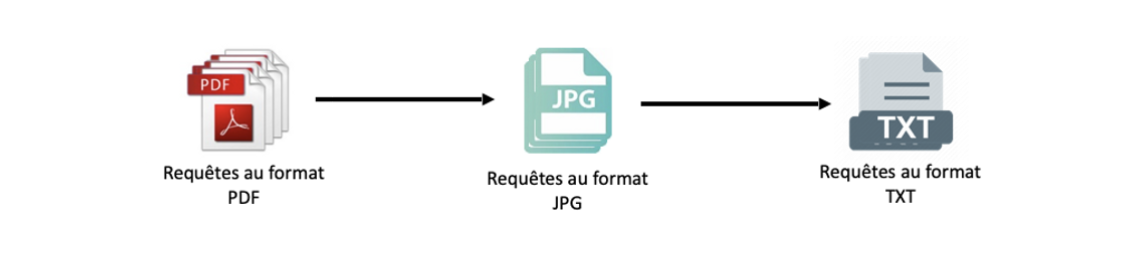
L’exactitude du processus OCR est cruciale, car elle impacte directement la qualité des données utilisées dans les étapes de traitement suivantes.
Traitement des Données (2 - Données)
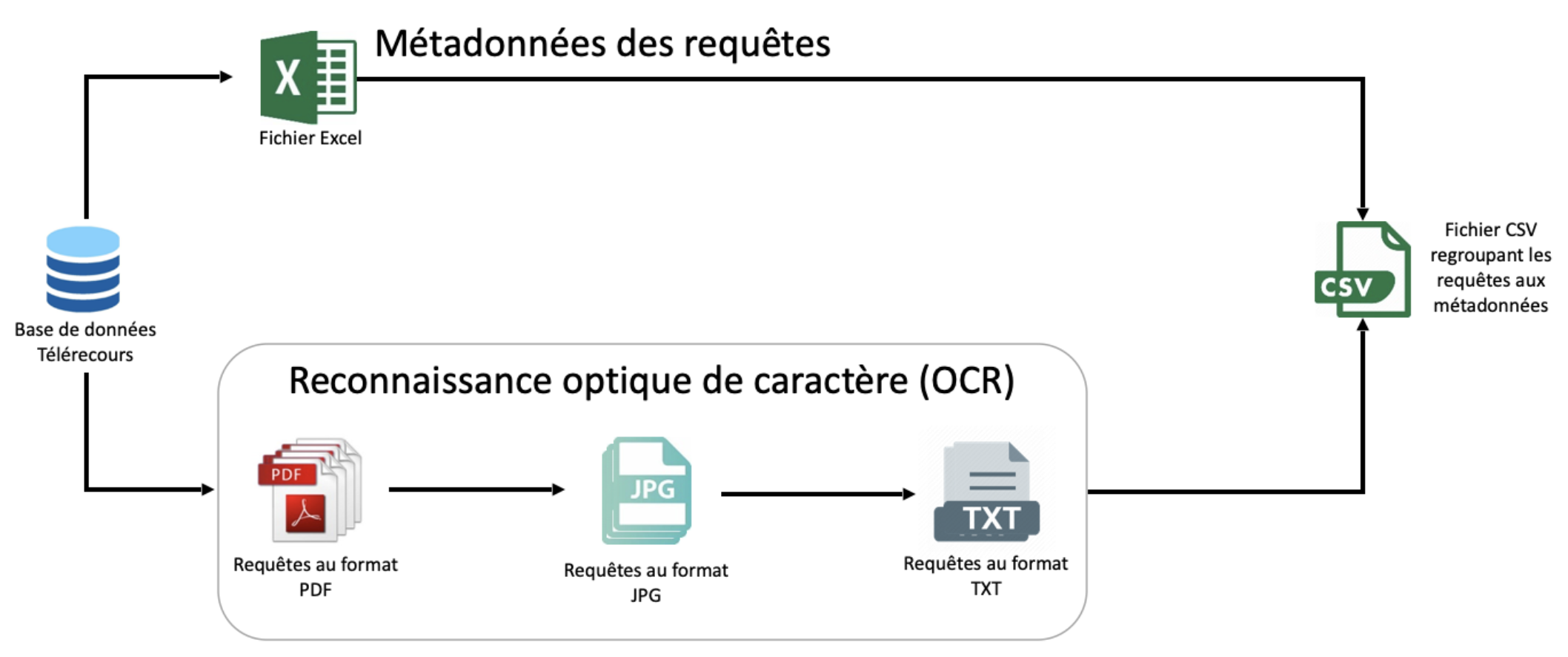
Dans cette section, les données brutes issues du processus OCR sont nettoyées et préparées. Cela comprend la suppression du bruit (caractères non pertinents ou artefacts erronés) et la normalisation du format des données. L’objectif est d’obtenir un format structuré et cohérent, prêt pour l’analyse exploratoire et les étapes d’apprentissage automatique.
Exploration des Données (3 - Exploration des données)
Ce dossier est dédié à l’analyse exploratoire des données (EDA), où les données sont examinées afin de comprendre leur structure et leurs modèles sous-jacents. L’EDA consiste à générer des visualisations et des résumés statistiques permettant d’identifier des tendances, des anomalies et des relations potentielles.
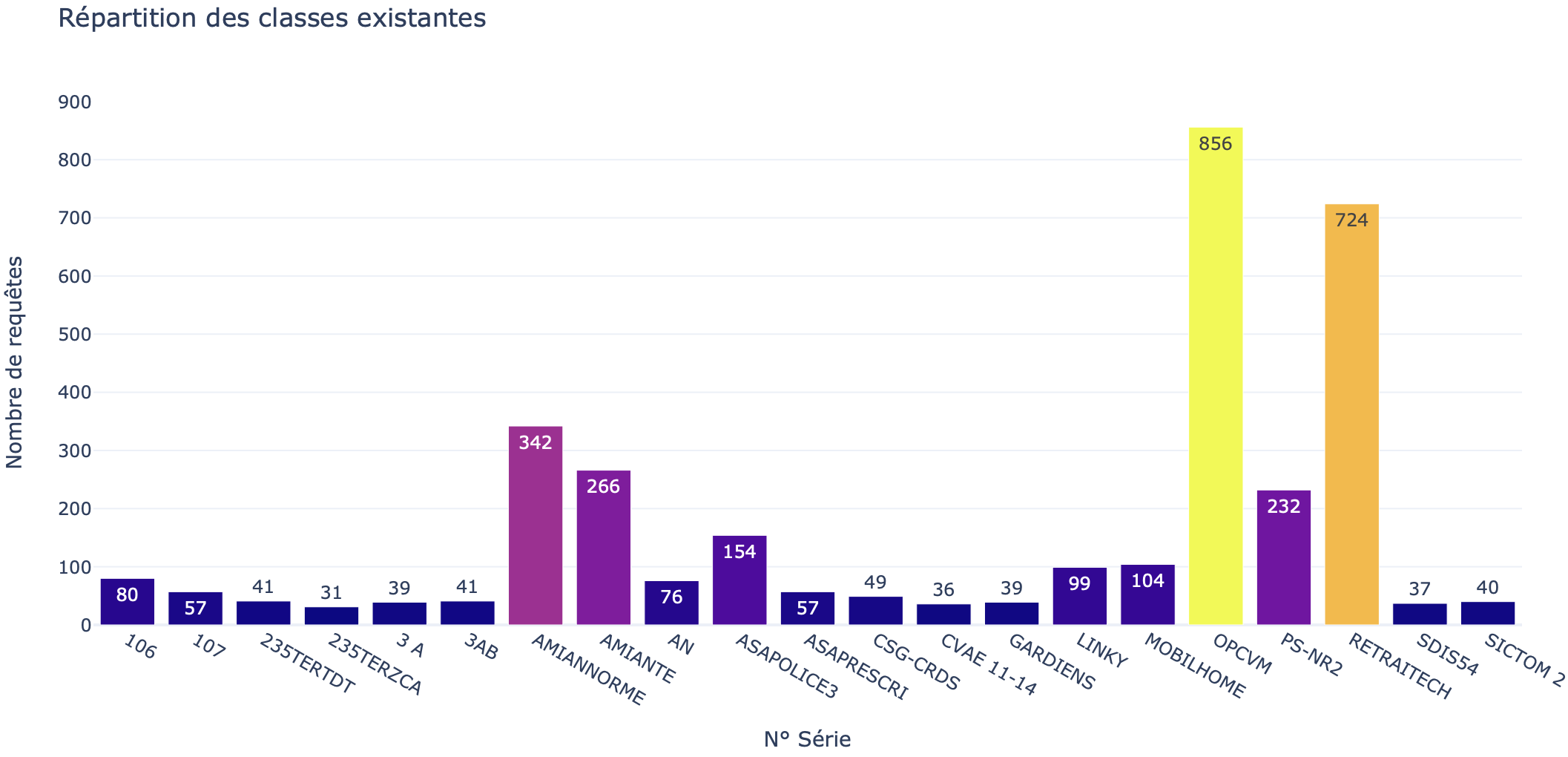
Ces informations sont essentielles pour orienter le choix des techniques de modélisation et pour mieux comprendre les caractéristiques des requêtes juridiques.
Traitement du Texte (4 - Text Processing)
À cette étape, diverses techniques de traitement du texte sont appliquées aux données nettoyées afin de les préparer pour l’apprentissage automatique. Des méthodes comme la racinisation (réduction des mots à leur forme de base) et la lemmatisation (conversion des mots en leur forme canonique) sont utilisées.
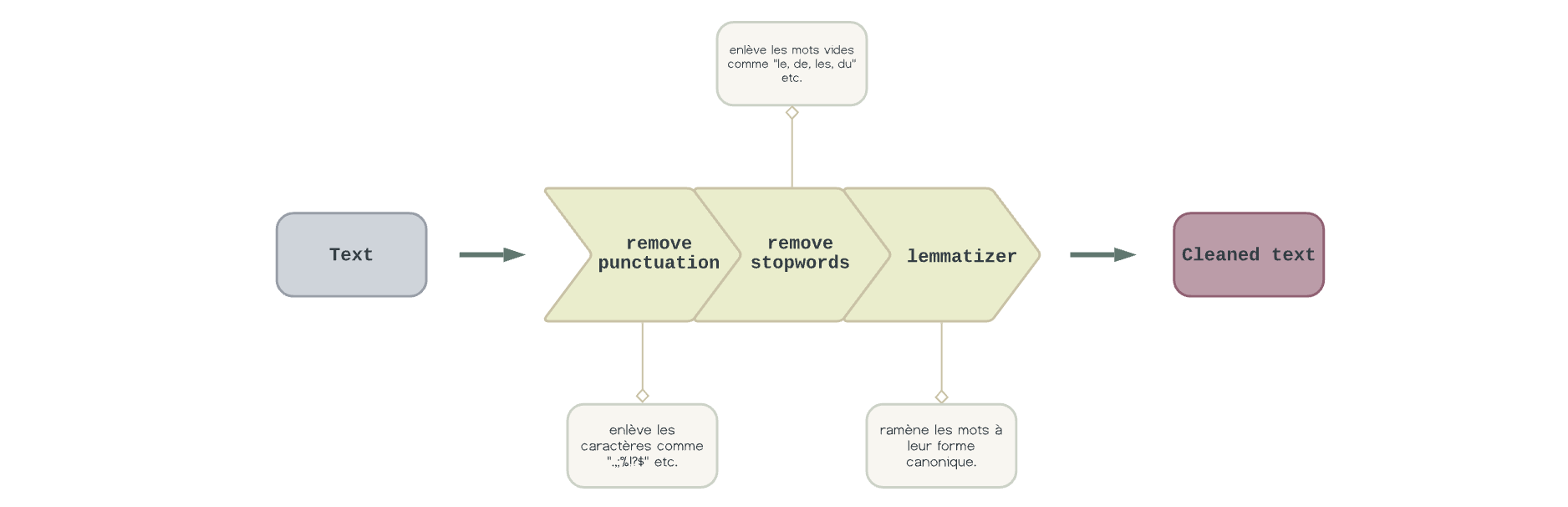
De plus, cette phase peut inclure des méthodes de vectorisation comme TF-IDF (Term Frequency-Inverse Document Frequency) pour transformer le texte en caractéristiques numériques exploitables par les modèles d’apprentissage automatique.
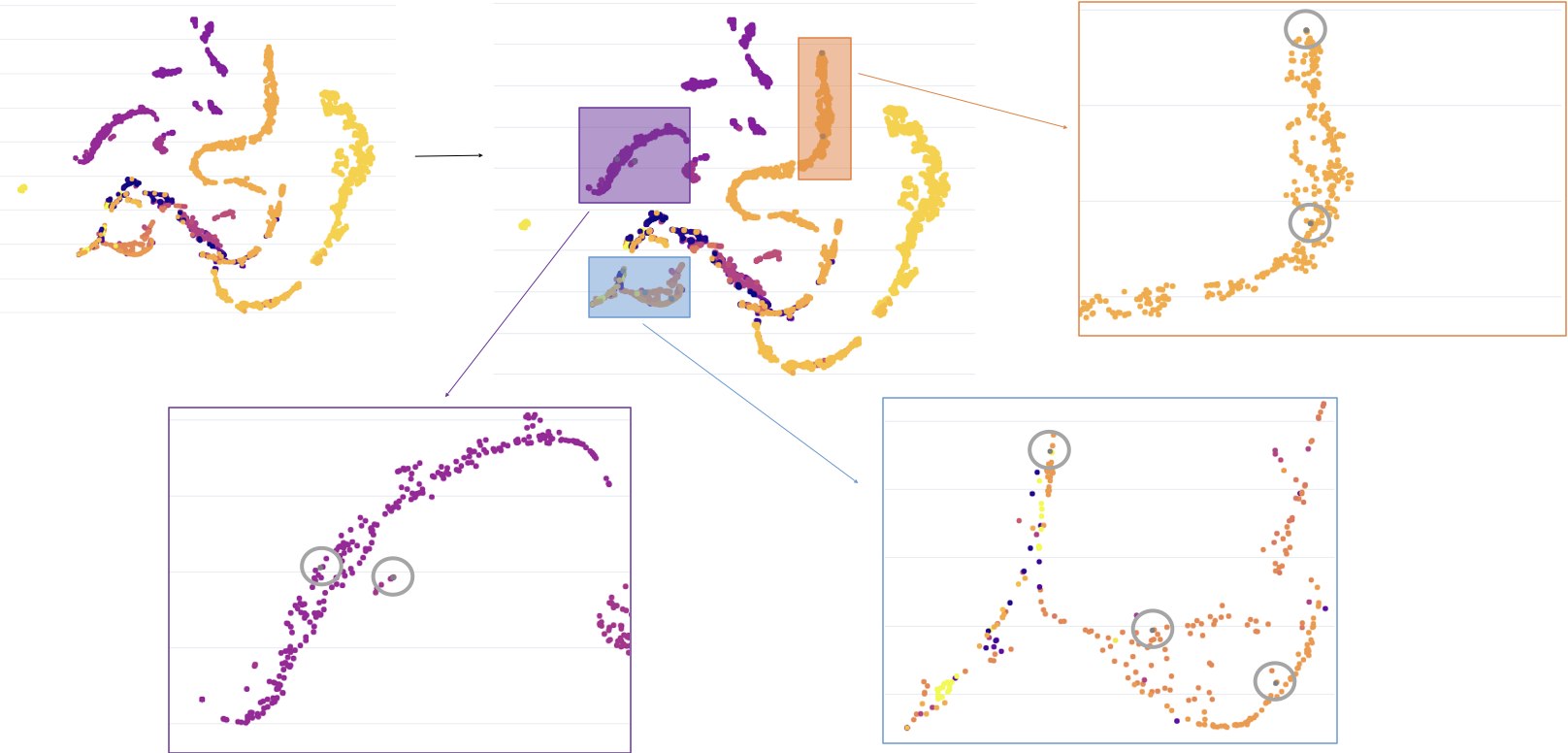
Réduction de Dimension (5 - Réduction de dimension)
Les données textuelles traitées, maintenant sous forme numérique, contiennent souvent un grand nombre de caractéristiques.
Des techniques de réduction de dimension comme PCA (Analyse en Composantes Principales) ou t-SNE (t-distributed Stochastic Neighbor Embedding) sont utilisées pour diminuer le nombre de dimensions tout en conservant les aspects les plus informatifs des données.
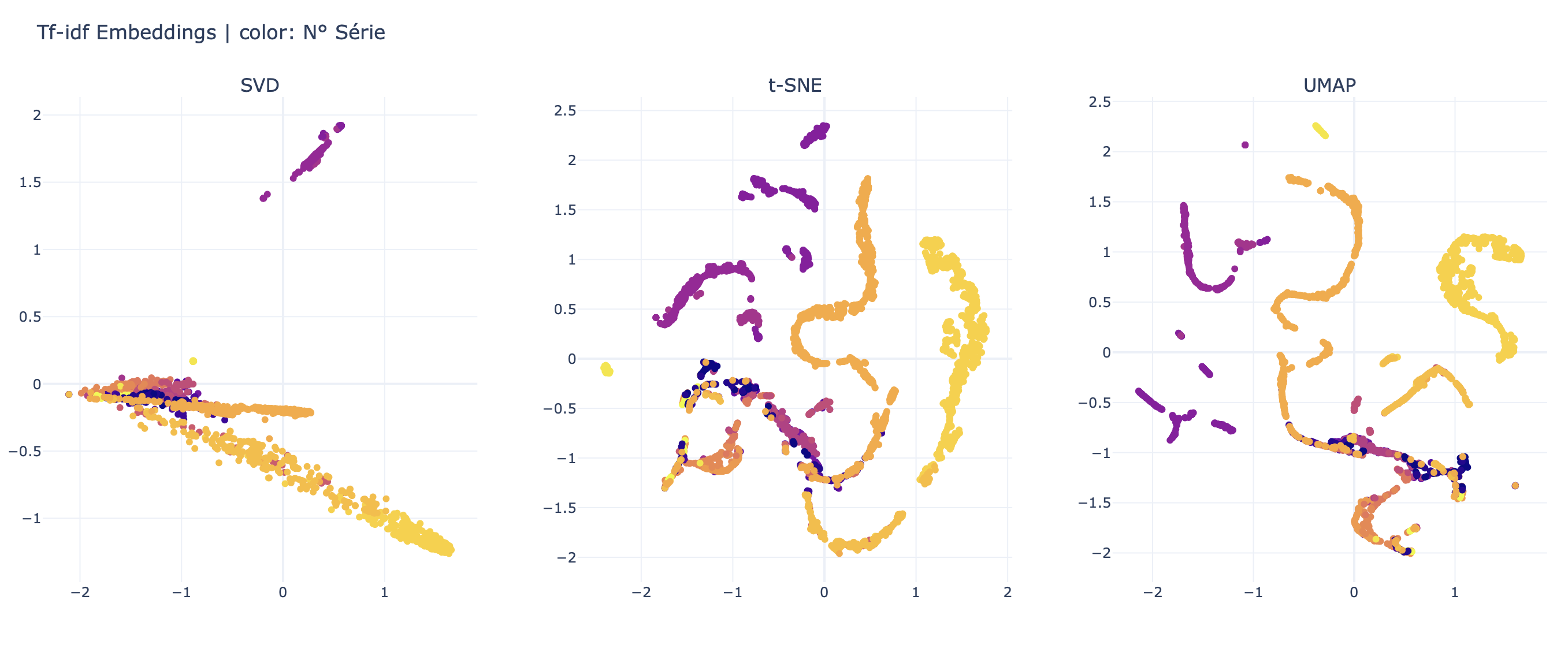
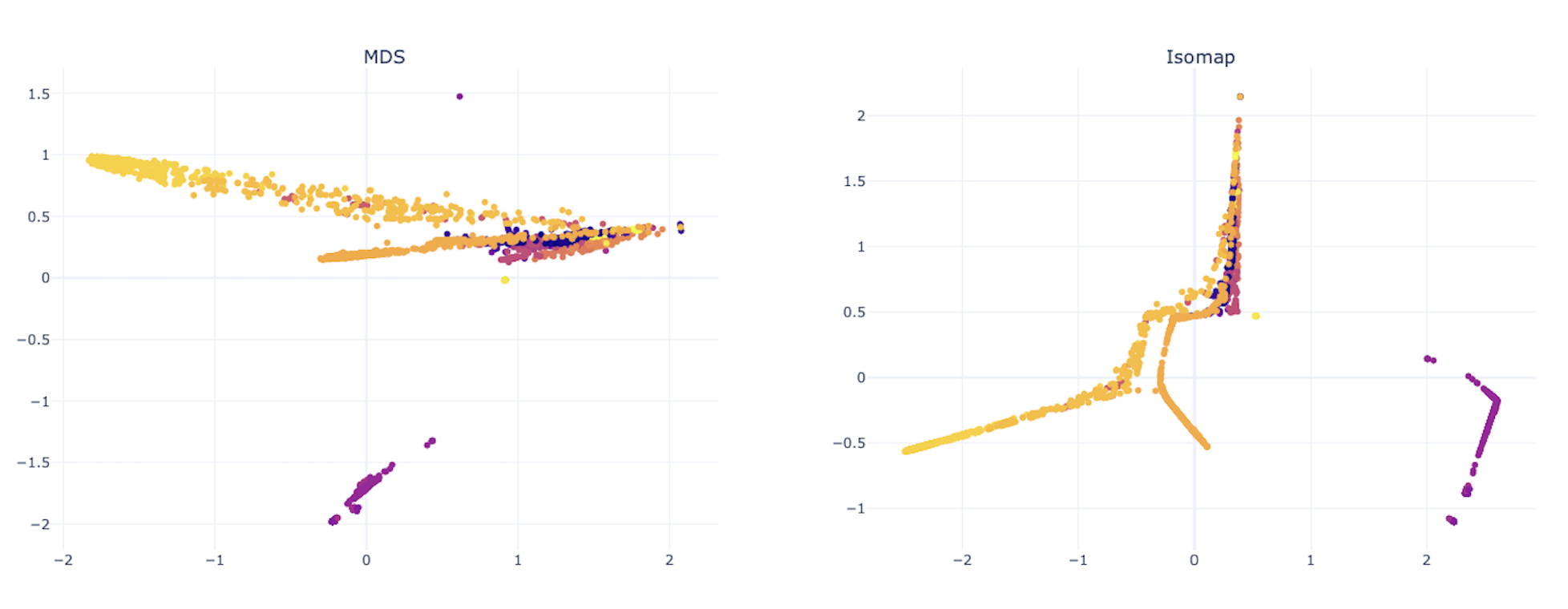
Cela permet d’améliorer l’efficacité des modèles d’apprentissage automatique tout en rendant les données plus interprétables.
Stratégie de Division des Données (6 - Stratégie de division des données)
La méthode StratifiedShuffleSplit a été utilisée ici. Cette technique de validation croisée vise à préserver la distribution des classes dans les ensembles d’entraînement et de test.
Elle garantit que la proportion de chaque classe reste constante dans les deux ensembles, ce qui est particulièrement important en présence de classes déséquilibrées.
L’algorithme fonctionne en mélangeant les données de manière aléatoire, puis en les divisant tout en maintenant les proportions des classes.
Algorithmes d’Apprentissage Automatique (7 - Algorithmes)
Cette section se concentre sur l’implémentation de divers modèles d’apprentissage automatique pour classifier les requêtes juridiques.
Elle couvre l’ensemble du processus, de la sélection des algorithmes appropriés (forêts aléatoires, machines à vecteurs de support, réseaux neuronaux, etc.) à l’entraînement des modèles sur les données préparées, en passant par l’optimisation des hyperparamètres.
L’efficacité de chaque modèle est évaluée sur un ensemble de validation afin de sélectionner les meilleurs modèles pour le déploiement final.
Ajustement Fin (8 - Fine-Tuning)
Après l’entraînement initial des modèles, une optimisation supplémentaire est nécessaire pour obtenir la meilleure performance possible. Cette section détaille le processus de fine-tuning à l’aide de l’optimisation bayésienne.
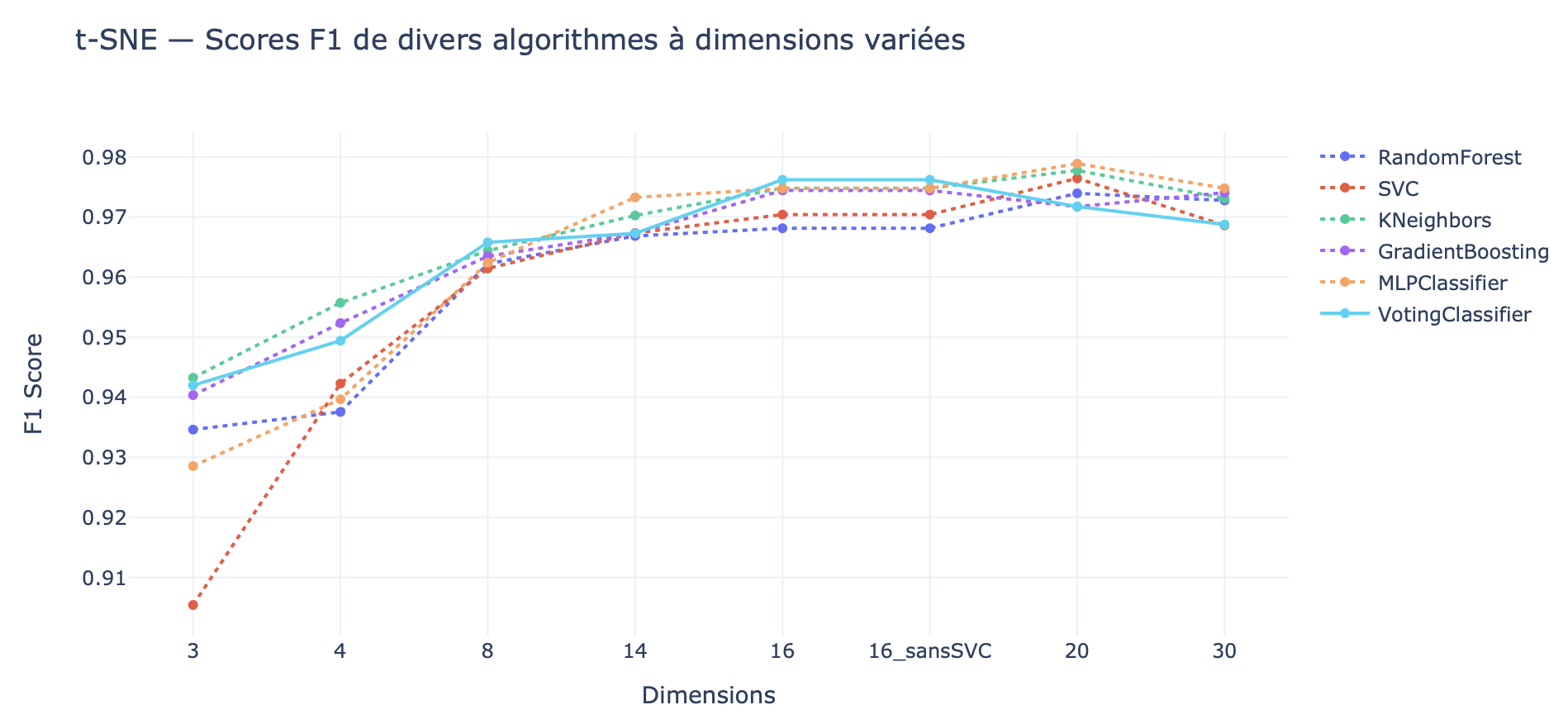
Évaluation et Comparaison (9 - Benchmark)
Les modèles développés sont rigoureusement évalués à l’aide de divers indicateurs de performance tels que l’exactitude, la précision, le rappel et le score F1.
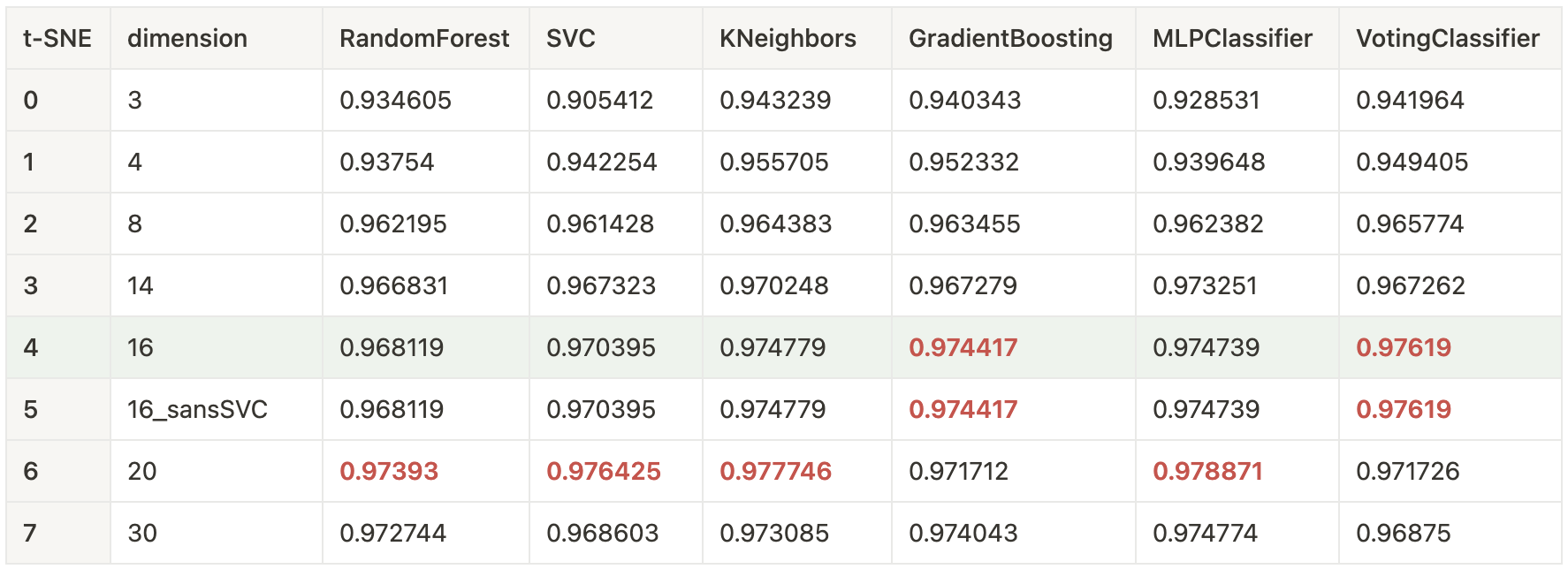
Ce dossier contient les résultats de ces évaluations, comparant différents modèles et configurations afin de déterminer la meilleure approche pour atteindre les objectifs du projet.
Développement de l’Application (10 - App)
L’étape finale du projet consiste à intégrer les modèles d’apprentissage automatique dans une application fonctionnelle.
Ce dossier contient le code de développement d’une application ou d’un tableau de bord permettant aux professionnels du Conseil d’État de classifier de nouvelles requêtes juridiques en temps réel.
L’application regroupe toutes les étapes précédentes et fournit une interface utilisateur intuitive exploitant la puissance des modèles entraînés pour automatiser et simplifier le processus de classification.
Confidentialité et Sécurité des Données
Étant donné la nature sensible des données juridiques, ce projet accorde une grande importance à la sécurité des données.
Aucune information confidentielle n’est incluse dans ce dépôt. Toutes les données sensibles ont été supprimées ou anonymisées, garantissant la conformité avec les réglementations en matière de protection des données.
Licence
Ce projet est partagé sous la licence GNU General Public License v3.0.