Ahmed OSMAN
Ingénieur IA chez Nuiva
En tant que Data Scientist passionné, je combine des compétences analytiques avancées avec une expertise en programmation et en modélisation pour résoudre des problèmes complexes et transformer les données en décisions éclairées.
Je travaille actuellement comme Ingénieur IA chez Nuiva, où je suis responsable du développement et du déploiement de modèles d'apprentissage automatique pour améliorer la performance des produits de l'entreprise.
![]()
![]()
![]()
Projets
Nuiva
![]()
AI-Agent — Génération de tests unitaires pour un serveur Spring Boot (Nuiva)
Développement d’un agent basé sur l’IA capable de générer, exécuter et affiner automatiquement des tests unitaires en Java pour les serveurs Spring Boot, en particulier pour les OpenAPIs de TMForum.
Lire plus →
Maintenance prédictive basée sur l’IA (Nuiva)
Ce projet intègre deux composants clés pour améliorer les systèmes de gestion des pannes :
- Détection des alarmes pertinentes : Un modèle de classification qui identifie si une alarme est pertinente (nécessitant une intervention) ou non (par exemple, alarmes transitoires).
- Maintenance prédictive : Un système de prévision qui anticipe les occurrences futures d’alarmes sur les 14 prochains jours, ainsi que leurs types respectifs.
Détection d’Intrusion Réseau
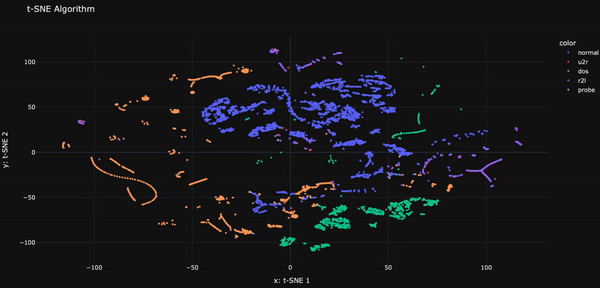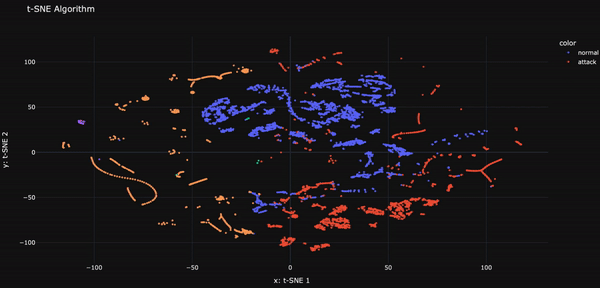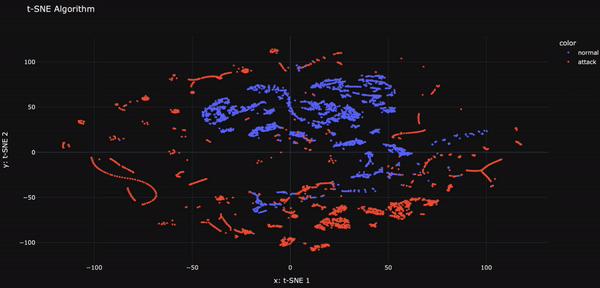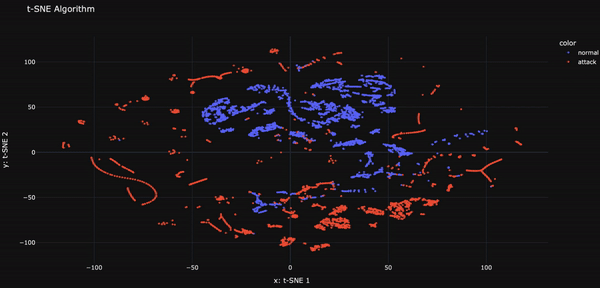 Ce projet développe un classificateur basé sur l’apprentissage automatique pour distinguer efficacement le trafic réseau intrusif (malveillant) du trafic non intrusif (bénin). Un prétraitement avancé et l’utilisation de SMOTE améliorent la capacité de détection, rendant ce système particulièrement performant dans l’identification des attaques.
Ce projet développe un classificateur basé sur l’apprentissage automatique pour distinguer efficacement le trafic réseau intrusif (malveillant) du trafic non intrusif (bénin). Un prétraitement avancé et l’utilisation de SMOTE améliorent la capacité de détection, rendant ce système particulièrement performant dans l’identification des attaques.
Présentation du projet → Présentation animée
| Graphiques interactifs | Liens |
|---|---|
| Graphique 2D | visualisation |
| Graphique 3D | visualisation |
Détection automatique des séries de requêtes juridiques - Conseil d’État de France
![]() Dans le cadre de mon Master en Data Science à l’Université Paris-Saclay, ce projet a été réalisé lors de mon apprentissage au Conseil d’État. Il visait à automatiser la classification des séries de requêtes juridiques, améliorant ainsi considérablement l’efficacité, la précision et la fiabilité des processus de gestion des données de l’institution.
Dans le cadre de mon Master en Data Science à l’Université Paris-Saclay, ce projet a été réalisé lors de mon apprentissage au Conseil d’État. Il visait à automatiser la classification des séries de requêtes juridiques, améliorant ainsi considérablement l’efficacité, la précision et la fiabilité des processus de gestion des données de l’institution.
(Version française)
Deep Contrastive Learning
 Ce projet utilise SimCLR, une méthode d’apprentissage contrastif, pour entraîner un modèle sur le jeu de données MNIST avec un minimum de données annotées. En exploitant des techniques non supervisées, il améliore la représentation des caractéristiques et permet une augmentation de 7% de la précision par rapport aux modèles traditionnels.
Ce projet utilise SimCLR, une méthode d’apprentissage contrastif, pour entraîner un modèle sur le jeu de données MNIST avec un minimum de données annotées. En exploitant des techniques non supervisées, il améliore la représentation des caractéristiques et permet une augmentation de 7% de la précision par rapport aux modèles traditionnels.
Prédiction du Turnover
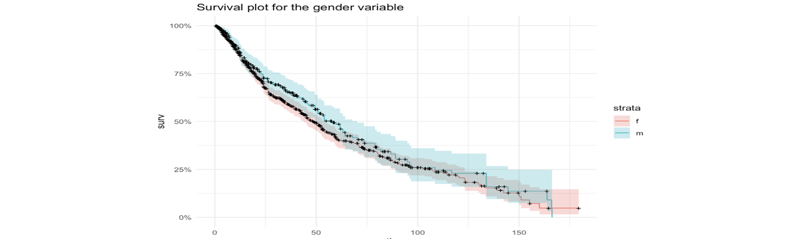 Ce projet vise à prédire le turnover des employés dans une entreprise en utilisant l’analyse de survie et des méthodes de classification en R. En comparant des modèles comme les Cox proportional hazards et les Survival Random Forests avec des approches classiques de classification, l’objectif est d’anticiper le risque de départ d’un employé dans l’année à venir afin d’optimiser la gestion des ressources humaines.
Ce projet vise à prédire le turnover des employés dans une entreprise en utilisant l’analyse de survie et des méthodes de classification en R. En comparant des modèles comme les Cox proportional hazards et les Survival Random Forests avec des approches classiques de classification, l’objectif est d’anticiper le risque de départ d’un employé dans l’année à venir afin d’optimiser la gestion des ressources humaines.